背景
现场的展会,需要同步播放多个视频。 要求多个视频的播放进度必须保持一致。
解决方案

- 建议使用windows笔记本作为主要pc控制端。
- 选择一款可以同时播放多个视频的播放器,下面会给出选择。
- 拼接多个显示屏幕(显示器或者投影仪)为一个屏幕墙,屏幕墙在操作系统中会识别成一个显示屏。一个播放器只能在一个显示屏上播放。
屏幕拼接接入
连接相关屏幕,有两种方式:有线与无线。
- 有线:优点是稳定的数据传输,缺点是受拼接处理器和HDMI线的限制,能够连接的屏幕数量以及连接距离都会比较受限。
- 无线:优先是解决了无线的缺点,缺点就是信号不够稳定,有时候视频会中断重连。
两种方式都可以配置多个屏幕为一个屏幕墙,在pc的显示配置中,可以看到接入一个分辨率非常大的显示屏。
有线
购买多屏拼接处理器,使用hdmi线组成一个显示器。(429元)

- 具体的配置可与客服沟通。
无线
使用spacedesk对同一个WIFI下的安卓/IOS/PC,设置进行投射,组成一个显示器。
建议购置一个稳定的路由器,否则可能会出现网络问题。推荐一个我在用的企业级路由器网件R8500价格428,测试了一晚上,没有出现断连问题。

播放器
选择随意一个可以播放多个视频的播放器即可,下面是两个测试过的。
hammultiplayer
官网
更为专业的软件,PC端可以作为统一监控界面。 学习成本高。


gridplayer
- 打开下载好的播放器文件。

- 在播放器上点击右键,选择视频的排列方式。

- 请注意配置参数 size ,选择一行最多可显示的视频个数。
- 拖动要同时播放的文件到窗口内。

- 右键:all 操作,统一操作视频。

- play/pause: 统一控制 播放/暂停。
- jump: 统一跳转到对应播放进度。

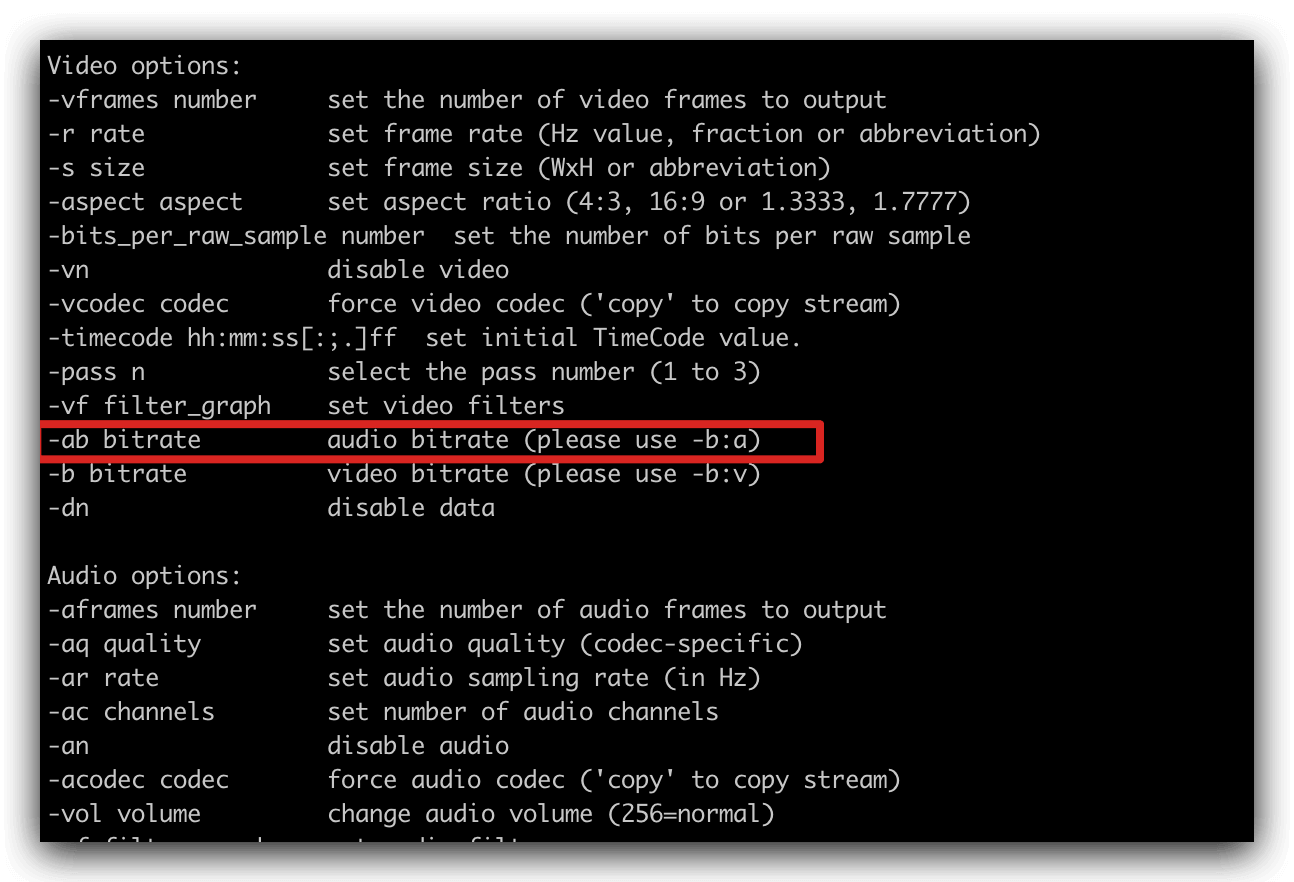 发现音频怎么也改不过去, 然后意识到这个是 视频的参数。
发现音频怎么也改不过去, 然后意识到这个是 视频的参数。
 简单的理解,应该是使用在不通场景的编码格式。
简单的理解,应该是使用在不通场景的编码格式。